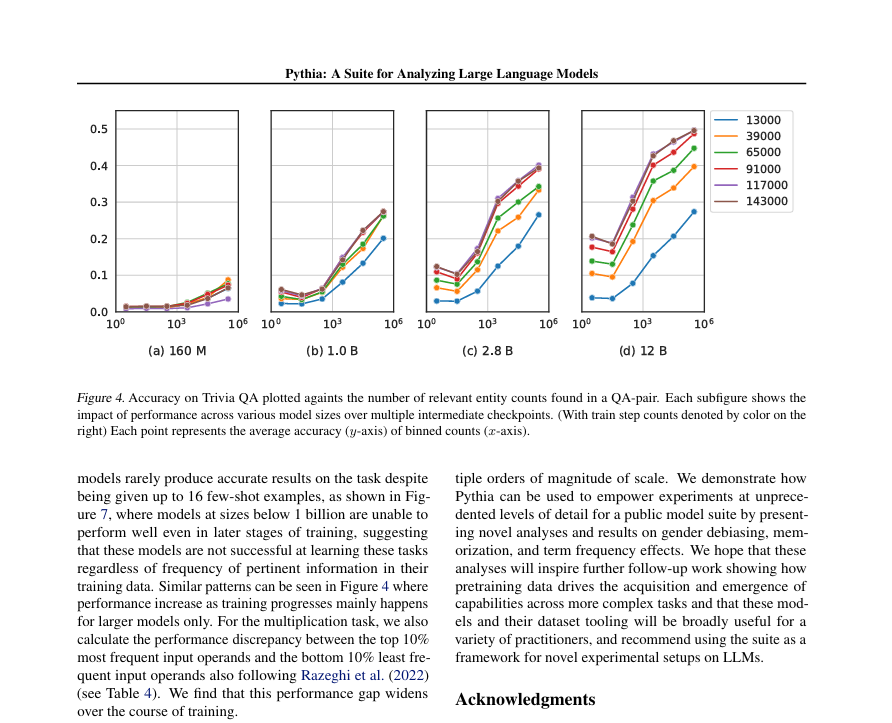
PRINCETON — Princeton researchers have upended conventional reinforcement learning by demonstrating that AI agents can learn faster without step-by-step feedback. In a study that challenges established training paradigms, simulated robots were assigned a single, difficult task with no guided feedback—and they succeeded, often outperforming robots trained with detailed rewards and instructions.
Reinforcement learning typically relies on iterative trial and error, where agents receive rewards and feedback as they progress toward a goal. However, the Princeton team, led by researchers Ben Eysenbach and Grace Liu, discovered that removing these intermediate signals forces the AI to explore its environment more creatively. “This isn’t the typical method,” Liu, now a doctoral student at Carnegie Mellon, remarked, highlighting the initially counterintuitive nature of the approach.
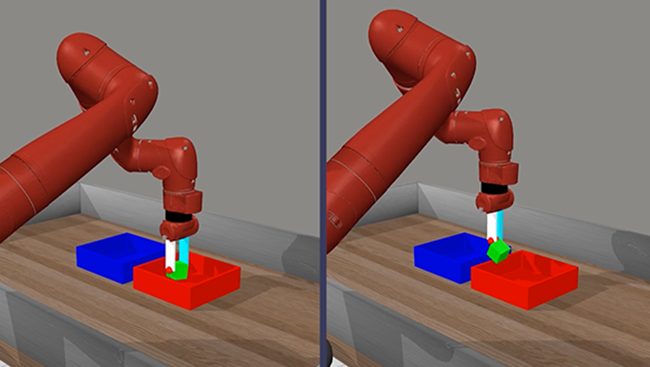
In experiments where robots were simply told to move green blocks into a blue box, the machines exhibited behaviors described as “almost childlike.” Instead of following a pre-scripted sequence, the robots experimented with various strategies—playing with the block, testing its movement, and even engaging in playful antics reminiscent of a game of table tennis. Eysenbach noted that the emergent exploratory behavior bore an intriguing, albeit informal, resemblance to aspects of human child development.
Beyond enhancing performance, the new method simplifies the training process. Traditional reinforcement learning frameworks often require extensive code to provide nuanced instructions at various stages of task completion. By contrast, the Princeton approach reduces this complexity to a single clear objective: “Here’s where we want you to go. Figure out how to get there on your own.” This streamlined process could lower the barrier to entry, enabling scientists and engineers to adopt advanced reinforcement learning techniques with less effort and greater ease.
The findings, detailed in the paper titled A Single Goal is All You Need: Skills and Exploration Emerge from Contrastive RL without Rewards, Demonstrations, or Subgoals, will be presented at the 2025 International Conference on Learning Representations in Singapore. The study, which also credits undergraduate researcher Michael Tang, signals a potential paradigm shift in how AI systems can be trained to explore and solve complex tasks without the crutch of incremental feedback.
Princeton’s breakthrough not only challenges long-held assumptions in AI research but also opens the door for more efficient, scalable, and user-friendly reinforcement learning applications across various fields.
In the context of AI, what’s the radical shift here?
The radical shift is removing step-by-step rewards and feedback, forcing AI agents to learn solely through exploration by being given only a single, challenging goal. This approach simplifies the training process while fostering innovative, emergent strategies in AI behavior.