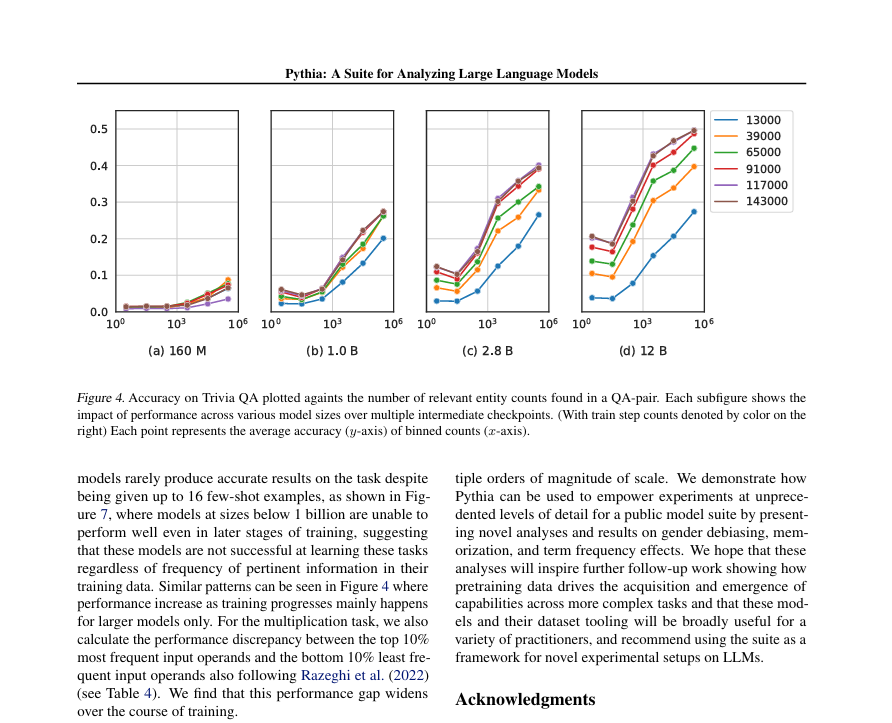
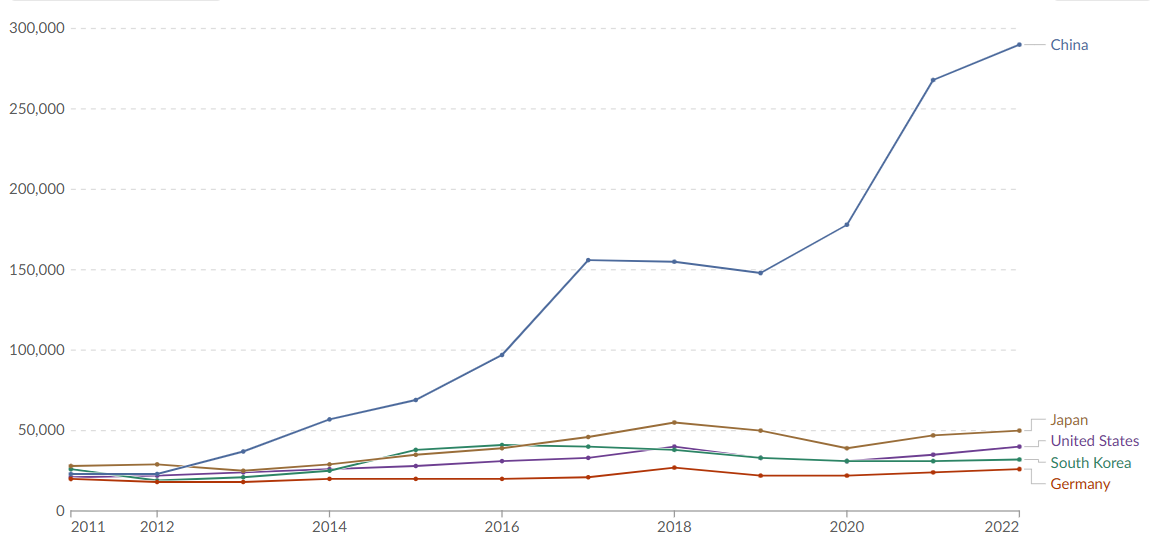
SAN FRANCISCO — OpenAI has announced the availability of fine-tuning for GPT-3.5 Turbo, allowing developers to customize the model for specific use cases. Fine-tuning for GPT-4 is expected to follow this fall. This new capability enables developers to enhance model performance, providing better tailored outputs for their applications. Early tests indicate that a fine-tuned GPT-3.5 Turbo can match or surpass base GPT-4 performance on certain tasks.
Key Use Cases for Fine-Tuning:
- Improved Steerability: Businesses can fine-tune models to follow instructions more accurately, such as always responding in a specific language or maintaining a particular output style.
- Reliable Output Formatting: Fine-tuning ensures consistent response formatting, which is essential for tasks like code completion or generating API calls.
- Custom Tone: Fine-tuning allows the model to align better with a business’s brand voice, maintaining a consistent tone in its outputs.
Fine-tuning not only enhances performance but also reduces the length of prompts, saving time and costs. The updated GPT-3.5-Turbo can handle 4k tokens, twice the capacity of previous models. Early testers have managed to reduce prompt size by up to 90% by embedding instructions directly into the model.
Combining fine-tuning with other techniques, such as prompt engineering and function calling, can further optimize performance. Support for fine-tuning with function calling and gpt-3.5-turbo-16k is anticipated later this fall.
For more details, developers can refer to OpenAI’s fine-tuning guide.