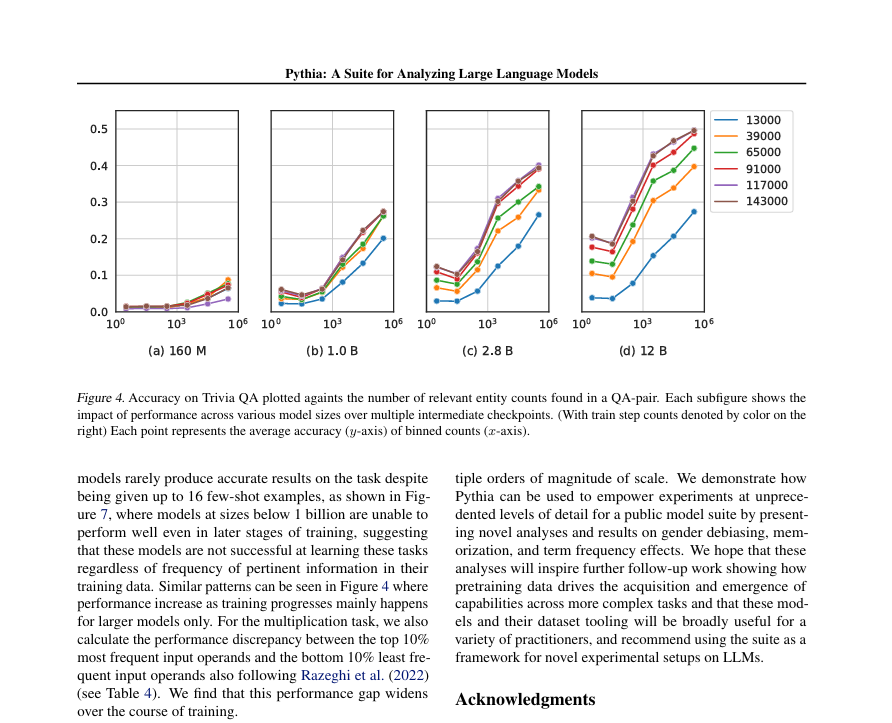
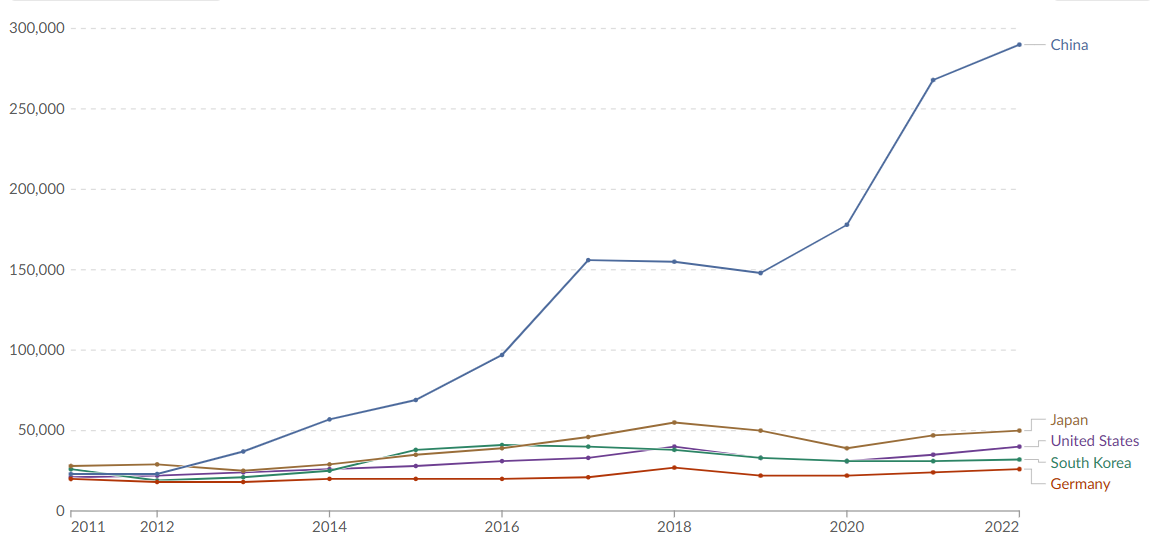
MENLO PARK — On May 12, 2020, Facebook AI introduced a new dataset and competition aimed at advancing the detection of multimodal hate speech, which includes both text and images. The Hateful Memes dataset, containing over 10,000 examples, was created to help AI researchers develop systems capable of understanding and identifying harmful content that blends multiple modalities. To support this, Facebook AI licensed images from Getty Images and released code for baseline-trained models.
In conjunction with the dataset, Facebook AI has also launched the Hateful Memes Challenge, hosted by DrivenData, with a prize pool of $100,000. The challenge is designed to push the boundaries of AI research and is part of the NeurIPS 2020 competition track.
The goal of the project is to equip AI systems to process and understand multimodal content in the same holistic way humans do. This challenge is part of Facebook AI’s broader efforts to tackle harmful content, following initiatives such as the Deepfake Detection Challenge and the Reproducibility Challenge.
The dataset was carefully curated to present difficult multimodal cases that cannot be easily identified by unimodal classifiers. By creating this resource, Facebook AI aims to promote collaboration within the AI research community to address the evolving problem of harmful content.